Architectural challenges on integrating ifood
Here at Mimic we have a very ambitious goal of being the OS (Operational System) of kitchens, and to do that we believe we should (allowing restaurants either to) integrate with every possible aggregator. All of them have their own very specific particularities, which made me think it would be good to share challenges we faced when integrating with ifood.
If you don't know what "ifood" is: ifood is a Brazilian startup responsible for helping restaurants with delivery (analogous to Doordash or Uber Eats - we call this group restaurant "aggregators").
For obvious reasons, I'm not allowed to share real code, but I can and I will share abstractions, concepts, and describe real challenges and real architectural decisions.
Microservices ecosystem
In Mimic, we do care a lot about software quality and EDA (event-driven architecture). It allows us to have more teams working dynamically at several pieces without interfering in each other jobs.
I see it as a bunch of "lego bricks", I can replace or add pieces as I wish without ruining my or other team's art. That's powerful because as we scale and integrate with other aggregators (let's say Uber Eats) we should be able to do it fast, without affecting our current structure.
So here's a (very simplified) view from our architecture today:
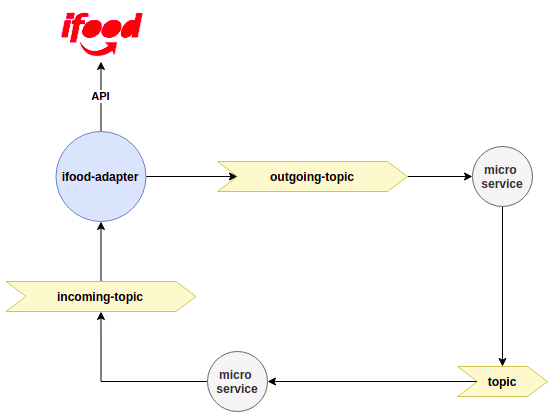
Note how any microservice willing to talk to ifood CAN'T. Actually, they don't even know it exists. Events are emitted through Kafka and they are agnostic to which aggregator it's talking to.
That's powerful to keep our small "lego city" up and running. We can easily replace or enhance a microservice without affecting businesses around our city. I want to plug Doordash? Don't worry, listen to this event, produce that other one, and voilà.
Given this overview let's move on to the technical challenges we faced and how we handled them.
Different client versions
The developer documentation is somewhat confusing.
First, their documentation is spread across 2 different links:
Second, they suggest you to use different client versions based on the endpoint, like:
- Poll events from here:
https://pos-api.ifood.com.br/v3.0/events:polling - Retrieve store details here:
https://pos-api.ifood.com.br/merchant/v2.0/merchants/merchant_id/availabilities - Notify you received your events:
https://pos-api.ifood.com.br/v1.0/events/acknowledgment
And no, I can't use v3.0 to all endpoints since it's the latest version. So our code must handle this complexity itself.
Finally, you test your integration in production
🤷
Sharing logic across inheritance
Inheritance seems a good way to get started:
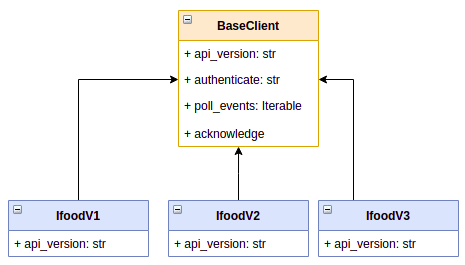
Why? Well, I believe you should not REPEAT YOURSELF (DRY principle). By doing this we can reuse the same authentication logic, the same logic for building URLs, the same logic for, well, everything but the API version.
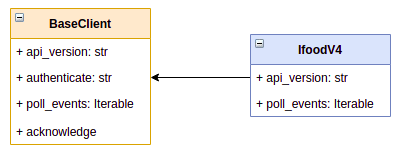
It also allows us to customize as we go. If later on, they decide to release a "poll events v4" with a different request method (let's say PATCH instead of POST), it would allow us to easily overwrite the method without affecting other working versions and methods:
Don't authenticate twice
Given the decision of inheriting and using custom clients for each API version, we might face the problem of authenticating. Assuming our pseudo-code is something like:
(all code you're about to see from now on is intentionally unreal, not working, and simple - also this is ugly, I don't deploy 💩 code to production)
import settings
class BaseClient:
@property
@abstractmethod
def api_version(self) -> str:
pass
def authenticate(self) -> str:
if not self.authentication:
token = settings.TOKEN
url = self.get_url()
requests.post(url, json=token)
self.authentication = requests.json()
def poll_events(self):
self.authenticate()
url = self.get_url()
headers = {"Authorization": f"Auth {self.authentication}"}
return requests.get(url, headers=headers).json()
class IfoodV1(BaseClient):
api_version = "v1.0"
class IfoodV2(BaseClient):
api_version = "v2.0"
class IfoodV3(BaseClient):
api_version = "v3.0"This just became a problem, because as you already know, whenever I use self I'm referring to the instance, so the following pseudo-code would trigger 3 authentications!
clientv1 = IfoodV1()
clientv2 = IfoodV2()
clientv3 = IfoodV3()
clientv1.poll_events() # authenticate, ok...
clientv2.poll_events() # authenticate again?
clientv3.poll_events() # authenticate again!!??The solution for this problem is to manage authentication as a class attribute instead of an instance one. So in the end it seemed similar to:
import settings
class AuthenticationHelper:
def set(self, token):
self.authentication = token
def get(self):
return self.authentication
class BaseClient:
authentication = AuthenticationHelper() # This is the trick!
@property
@abstractmethod
def api_version(self) -> str:
pass
def authenticate(self) -> str:
if not self.authentication:
token = settings.TOKEN
url = self.get_url()
requests.post(url, json=token)
self.authentication.set(requests.json())
def poll_events(self):
self.authenticate()
url = self.get_url()
headers = {"Authorization": f"Auth {self.authentication.get()}"}
return requests.get(url, headers=headers).json()
class IfoodV1(BaseClient):
api_version = "v1.0"
class IfoodV2(BaseClient):
api_version = "v2.0"
class IfoodV3(BaseClient):
api_version = "v3.0"Picking the correct client for the job
The proposal of keeping clients split by version and allowing them to extend worked fine. Well, it came with a problem... When to use which? And for what?
As described in ifood documentation, we must first poll events using v3 and then acknowledge we received them with v1... Ok.
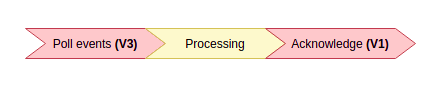
The worst scenario ever would be:
clientv1 = IfoodV1()
clientv3 = IfoodV3()
def do_the_thing(events):
# complex processing of events
# kafka publishing
# other magic
clientv3.acknowledge_events(events)
def main():
events = clientv1.poll_events()
do_the_thing(events)
Why? It exposes too much detail to your business layer, it adds complexity, it's hard to review and to understand (why do we use different versions here? Shouldn't it be v3 for polling as well?). Please, don't ever expose implementation details to your business layer like this (it would be like specifying which database version you want to use whenever you invoke your ORM layer) - that's terrible.
Scopes to the rescue!
What would be a good solution? I suggest using a combination of a Factory and Scopes (this is not a design pattern, just a fancy enum). So given a scope, the factory decides which client you need.
Expected usage:
from enum import Enum
from factories import ClientFactory
client_factory = ClientFactory()
class IfoodAPIScopes(Enum):
POLL_EVENTS = "V3"
SOMETHING_ELSE = "V3"
ACK_EVENTS = "V1"
THAT_OTHER_THING = "V1"
def do_the_thing(events):
# complex processing of events
# kafka publishing
# other magic
client = client_factory.get_best_client(IfoodAPIScopes.ACK_EVENTS)
client.acknowledge_events(events)
def main():
client = client_factory.get_best_client(IfoodAPIScopes.POLL_EVENTS)
events = client.poll_events()
do_the_thing(events)See how interesting this code is.
- Can I see which versions we're using and for what? Yes, see the scopes enum.
- Ifood just announced that acknowledge now uses v2! Cool, update the scope enum - business logic code will keep untouched! How easy would be to review that?
- Hey, there's a very complex scenario where we should use v1 every Friday! The factory class can contain this kind of logic without affecting the regular business flow.
The code now is split by behavior: Flow does not rely on implementation details, it just cares about intention (scope), so it's easy to read and understand (thus is maintainable).
Acknowledge events in batch
Let's narrow down deeper into our do_the_thing function which processes and forwards all events received. Since we need to process each one individually and ifood requires us to acknowledge we received every event otherwise they keep sending it forever to us.
Considering we receive 100 events in a single poll request, it would be terrible to iterate doing HTTP requests over them, right? It clearly wouldn't scale. That's why ifood provides us the acknowledgment endpoint with a batch operation, so we can POST to their API only once per batch.
Easy, right?
def do_the_thing(events):
for event in events:
process(event)
publish_to_kafka(event)
magic(event)
client = client_factory.get_best_client(IfoodAPIScopes.ACK_EVENTS)
client.acknowledge_events(events)Well, not quite easy. Keep in mind that if for any reason an individual event handling fails and throws an exception it will break the flow before notifying ifood.
Not just that, what if we received 100 events, and after processing 99 events the 100th one breaks? We never acknowledged anything. On the next iteration guess what? Yes, we're looping over the 99 events all over again. That doesn't seem wise.
Another approach would be to sacrifice performance and do it one by one:
def do_the_thing(events):
client = client_factory.get_best_client(IfoodAPIScopes.ACK_EVENTS)
for event in events:
try:
process(event)
publish_to_kafka(event)
magic(event)
except Exception:
logger.exception("Houston, we have a problem!")
else:
client.acknowledge_events(event)This doesn't seem smart either. That's where a Context Manager will suit well!
You probably used one when you had to iterate over some text file, like:
with open("test.txt") as f:
data = f.read() The trick in the sample above is that it:
- Give you a
fvariable containing the "file" you just opened for read - Automatically closes the file as soon as you leave the code block - either due to success or failure
Well, call me Guido van Rossum because I'm about to implement a Context Manager as well! This is what I expect:

The implementation now is:
class AcknowledgmentContextManager:
def __init__(self, client):
self.client = client
self.pending_ack = []
def ack(self, event):
self.pending_ack.append(event)
def __enter__(self):
return self
def __exit__(self, exc_type, exc_value, exc_traceback):
self.client.acknowledge_events(self.pending_ack)
def do_the_thing(events):
client = client_factory.get_best_client(IfoodAPIScopes.ACK_EVENTS)
# As soon as the next block ends, the client will trigger a
# request to the api only with successful events
with AcknowledgmentContextManager(client) as context:
for event in events:
try:
process(event)
publish_to_kafka(event)
magic(event)
except Exception:
logger.exception("Houston, we have a problem!")
else:
# Registers the event as successful
# Note NONE API request has been triggered
context.ack(event)Beware the power of the context manager. It's easy to read and easy to implement. Every single successful event is registered to our context and as soon as it ends - only then it will trigger an API request and only for successful events. It means the next polling we're going to receive only failing ones for reprocessing which is intended.
What do you think? Could I've done something better to scale and keep the microservice maintainable? Would you do something different? Get in touch! I'm always open to new ideas.
